What is it?
Genus

Genus
Starting off our project, we were trying to get as much data from the dataset as possible. To make it easier, we used different graphs that represent correlations between data columns inside the dataset. On this graph, we can see the correlation between the song tempo that is most commonly used in each individual genre and the popularity of that song.
This scatterplot helps to show the massive overlap between certain features of songs, in this case tempo and loudness. While there are some clear clusters of genres at certain loudness ranges, many genres overlap throughout these clusters, which makes it especially difficult for a computer to differentiate between genres.
This 3d scatterplot takes into account song duration, loudness, and popularity on the x-y-z axis as well as a song's energy determining the size of the point. Although there still is overlap, this helps to show that as more variables are taken into account, each song begins to appear as more unique, allowing more patterns to be seen across genres.
Here is a heat map that shows the correlation between different variables in each song. Some variables show greater correlation than others, such as energy and loudness, while other variables are less correlated. Greater correlation would make it easier to find patterns across genres, so because there are many variables with correlation close to zero, the computer will have a difficult time comparing many of the song parameters.

Logistic Regression is a Machine Learning classification algorithm that is used to predict the probability of a categorical dependent variable. In logistic regression, the dependent variable is a binary variable that contains data coded as 1 (yes, success, etc.) or 0 (no, failure, etc.).
Multinomial Logistic Regression is a type of Logistic Regression that deals with cases when the target or independent variable has three or more possible values. In our case, there are 10.
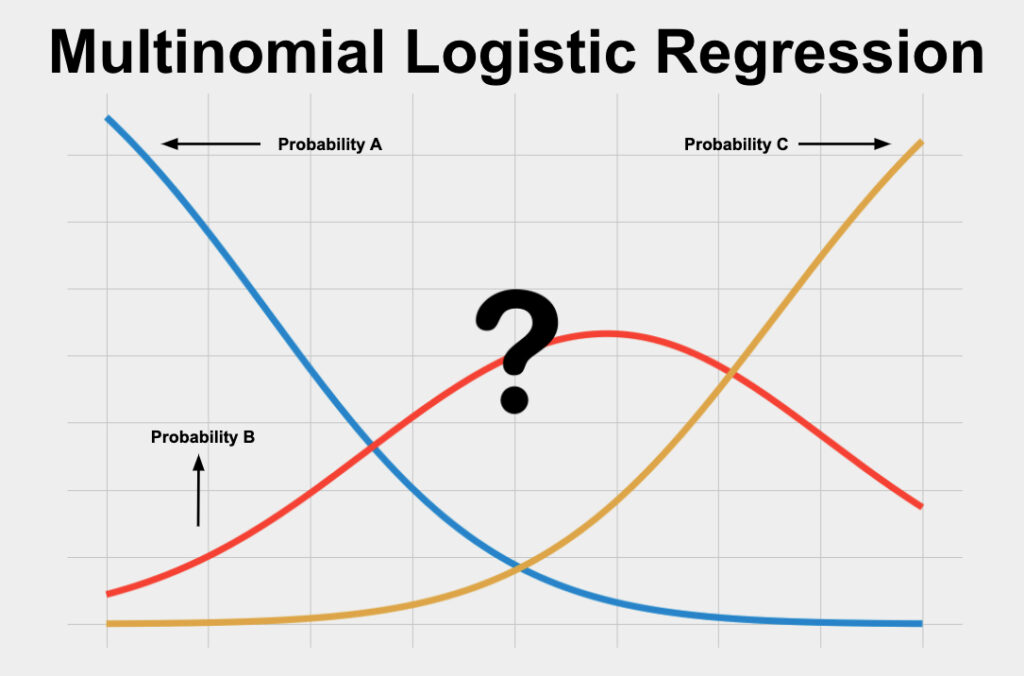
- Logistic regression is easier to implement, interpret, and very efficient to train.
- Good accuracy for many simple data sets and it performs well when the dataset is linearly separable.
- It can easily extend to multiple classes(multinomial regression) and a natural probabilistic view of class predictions.
- It can only be used to predict discrete functions. (Classes)
- It constructs linear boundaries. (In opposed to curvilinear)
- It is tough to obtain complex relationships using logistic regression.

Confusion matrix on the right, you can see the accuracy of Logistic Regression model that we used for the data set. On the y-axis are the actual values, and on the x-axis are predictions of these genres that were made used by the LR model. Thus, the higher the number is, the more accurate the predictions are.
From this graph, we can see that the most accurate predictions were made for Classical music, and the least accurate for Alternative music.
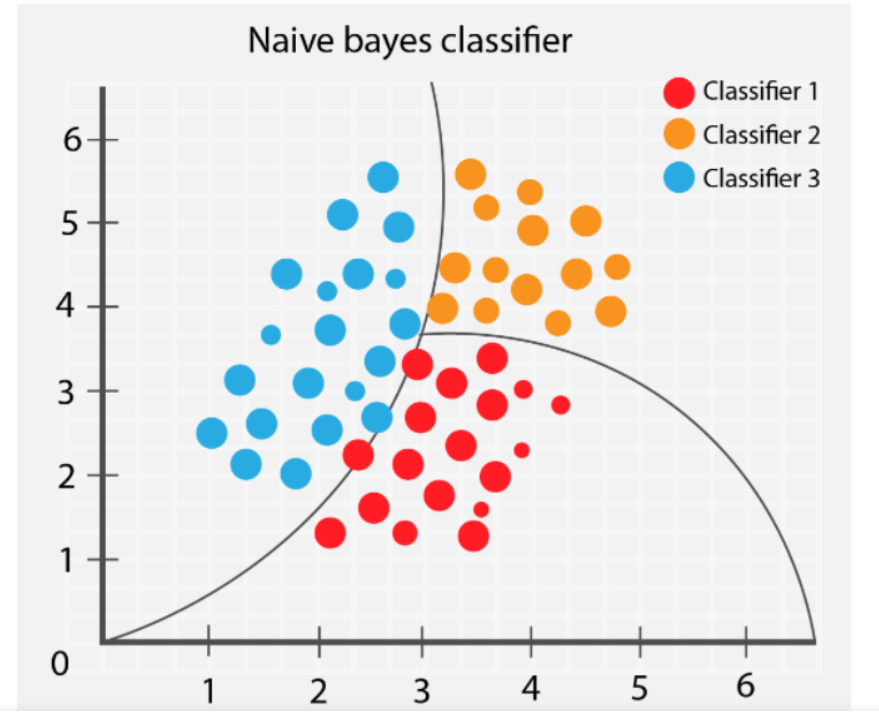
About Naive Bayes : Native Bayes is a machine learning
model for classification that uses the Bayes Theorem( 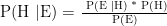
- P(H) is the probability of hypothesis H being true. This is
known as the prior probability.
- P(E) is the probability of the evidence(regardless of the
hypothesis).
- P(E|H) is the probability of the evidence given that
hypothesis is true.
- P(H|E) is the probability of the hypothesis given that the
evidence is there.

About Classification Trees:
Decision Trees (DTs) are a non-parametric supervised
learning method used
for classification and regression. The goal is
to create a model that predicts the value of a target variable
by learning simple decision rules inferred from the data
features. A tree can be seen as a piecewise constant
approximation.
Pros
- Simple to understand and to interpret. Trees can be
visualized.
- Requires little data preparation.
- Able to handle both numerical and categorical data.
- Possible to validate a model using statistical tests.
Cons
- Decision\-tree learners can create over complex trees that
do not generalize the data well.
- Decision trees can be unstable because small variations in
the data might result in a completely different tree being
generated
- Predictions of decision trees are neither smooth nor
continuous, but piecewise constant approximations as seen in
the above figure.
- Decision tree learners create biased trees if some classes
dominate.

Random forest is a commonly-used machine learning algorithm
trademarked by Leo Breiman and Adele Cutler, which combines
the output of multiple decision trees to reach a single
result. Its ease of use and flexibility have fueled its
adoption, as it handles both classification and regression
problems.
Benefits
- Reduced risk of overfitting: Decision trees run the risk of
overfitting as they tend to tightly fit all the samples
within training data. However, when there’s a robust number
of decision trees in a random forest, the classifier won’t
overfit the model since the averaging of uncorrelated trees
lowers the overall variance and prediction error.
- Provides flexibility: Since random forest can handle both
regression and classification tasks with a high degree of
accuracy, it is a popular method among data scientists.
Feature bagging also makes the random forest classifier an
effective tool for estimating missing values as it maintains
accuracy when a portion of the data is missing.
- Easy to determine feature importance: Random forest makes
it easy to evaluate variable importance, or contribution, to
the model. There are a few ways to evaluate feature
importance. Gini importance and mean decrease in impurity
(MDI) are usually used to measure how much the model’s
accuracy decreases when a given variable is excluded.
However, permutation importance, also known as mean decrease
accuracy (MDA), is another importance measure. MDA identifies
the average decrease in accuracy by randomly permutating the
feature values in oob samples.
Challenges
- Time-consuming process: Since random forest algorithms can
handle large data sets, they can be provide more accurate
predictions, but can be slow to process data as they are
computing data for each individual decision tree.
- Requires more resources: Since random forests process
larger data sets, they’ll require more resources to store
that data.
- More complex: The prediction of a single decision tree is
easier to interpret when compared to a forest of them.

XGBoost is a popular supervised machine learning algorithm that tends to outperform many other algorithms.
Benefits
- XGBoost can be used for both regression and classification models and for large datasets.
- It provides highly accurate results by using more accurate approximations in order to find the best tree models.
Challenges
- XGBoost often takes much longer to run than other algorithms because of how system-heavy it is.
- Requires more resources: Like random forests, XGBoost can process
larger data sets, so it will require more resources to store
that data.
Our Data
- It is clear that even XGBoost has a difficult time determining the genre of music because of the many overlapping parameters. For example, the model classifies Hip-Hop music as Rap more than it classifies Hip-Hop correctly, as seen in the bottom row of the heat map.
- Using XGBoost with our data and messing with the model's parameters through trial and error, we were able to get a final accuracy of 66.6%.
Each model we used has a different percentage accuracy. Some are more accurate in predicting outcomes than others.
This bar graph shows the difference in accuracy in each of the models that we used. The decimal shown can be translated to the percent of accuracy. (ex 0.5 = 50%)
| Overveiw | |
|---|---|
| Model | Accuracy (in %) |
| Logistic Regression | 53 |
| Naive Bayes | 42 |
| Classification Trees | 44 |
| Random forest | 50 |
| Logistic Regression | 53 |
| XGBoost | 66 |